Backport #26179 by @CaiCandong
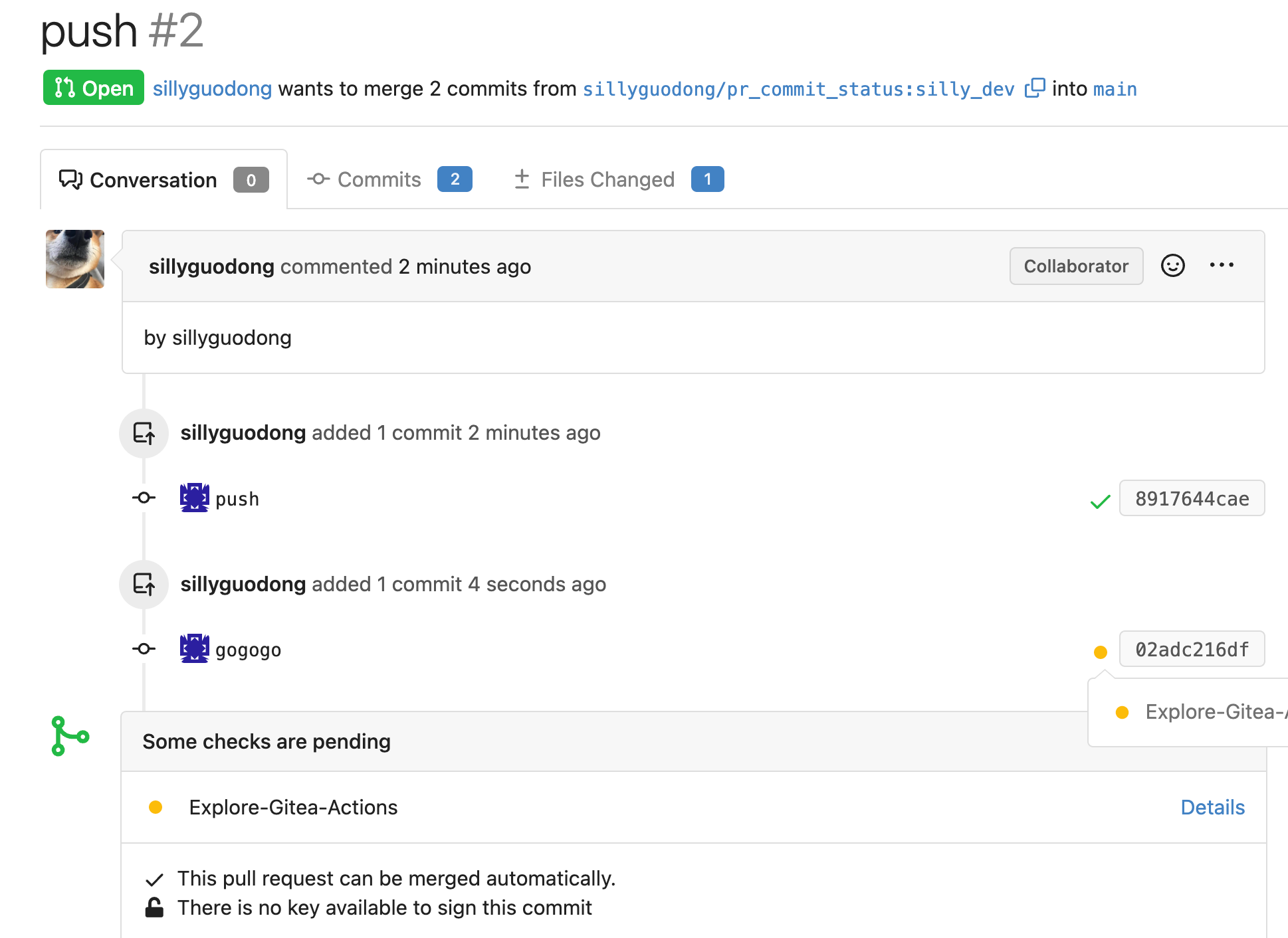
In the original implementation, we can only get the first 30 records of
the commit status (the default paging size), if the commit status is
more than 30, it will lead to the bug #25990. I made the following two
changes.
- On the page, use the ` db.ListOptions{ListAll: true}` parameter
instead of `db.ListOptions{}`
- The `GetLatestCommitStatus` function makes a determination as to
whether or not a pager is being used.
fixed#25990
Co-authored-by: caicandong <50507092+CaiCandong@users.noreply.github.com>
Backport #25560 by @wolfogreFix#25451.
Bugfixes:
- When stopping the zombie or endless tasks, set `LogInStorage` to true
after transferring the file to storage. It was missing, it could write
to a nonexistent file in DBFS because `LogInStorage` was false.
- Always update `ActionTask.Updated` when there's a new state reported
by the runner, even if there's no change. This is to avoid the task
being judged as a zombie task.
Enhancement:
- Support `Stat()` for DBFS file.
- `WriteLogs` refuses to write if it could result in content holes.
Co-authored-by: Jason Song <i@wolfogre.com>
Before there was a "graceful function": RunWithShutdownFns, it's mainly
for some modules which doesn't support context.
The old queue system doesn't work well with context, so the old queues
need it.
After the queue refactoring, the new queue works with context well, so,
use Golang context as much as possible, the `RunWithShutdownFns` could
be removed (replaced by RunWithCancel for context cancel mechanism), the
related code could be simplified.
This PR also fixes some legacy queue-init problems, eg:
* typo : archiver: "unable to create codes indexer queue" => "unable to
create repo-archive queue"
* no nil check for failed queues, which causes unfriendly panic
After this PR, many goroutines could have better display name:


This PR replaces all string refName as a type `git.RefName` to make the
code more maintainable.
Fix#15367
Replaces #23070
It also fixed a bug that tags are not sync because `git remote --prune
origin` will not remove local tags if remote removed.
We in fact should use `git fetch --prune --tags origin` but not `git
remote update origin` to do the sync.
Some answer from ChatGPT as ref.
> If the git fetch --prune --tags command is not working as expected,
there could be a few reasons why. Here are a few things to check:
>
>Make sure that you have the latest version of Git installed on your
system. You can check the version by running git --version in your
terminal. If you have an outdated version, try updating Git and see if
that resolves the issue.
>
>Check that your Git repository is properly configured to track the
remote repository's tags. You can check this by running git config
--get-all remote.origin.fetch and verifying that it includes
+refs/tags/*:refs/tags/*. If it does not, you can add it by running git
config --add remote.origin.fetch "+refs/tags/*:refs/tags/*".
>
>Verify that the tags you are trying to prune actually exist on the
remote repository. You can do this by running git ls-remote --tags
origin to list all the tags on the remote repository.
>
>Check if any local tags have been created that match the names of tags
on the remote repository. If so, these local tags may be preventing the
git fetch --prune --tags command from working properly. You can delete
local tags using the git tag -d command.
---------
Co-authored-by: delvh <dev.lh@web.de>
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Currently using the tip of main
(2c585d62a4) and when deleting a branch
(and presumably tag, but not tested), no workflows with `on: [delete]`
are being triggered. The runner isn't being notified about them. I see
this in the gitea log:
`2023/04/04 04:29:36 ...s/notifier_helper.go:102:Notify() [E] an error
occurred while executing the NotifyDeleteRef actions method:
gitRepo.GetCommit: object does not exist [id: test, rel_path: ]`
Understandably the ref has already been deleted and so `GetCommit`
fails. Currently at
https://github.com/go-gitea/gitea/blob/main/services/actions/notifier_helper.go#L130,
if the ref is an empty string it falls back to the default branch name.
This PR also checks if it is a `HookEventDelete` and does the same.
Currently `${{ github.ref }}` would be equivalent to the deleted branch
(if `notify()` succeded), but this PR allows `notify()` to proceed and
also aligns it with the GitHub Actions behavior at
https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#delete:
`$GITHUB_REF` / `${{ github.ref }}` => Default branch (main/master)
`$GITHUB_SHA` / `${{ github.sha }}` => Last commit on default branch
If the user needs the name of the deleted branch (or tag), it is
available as `${{ github.event.ref }}`.
There appears to be no way for the user to get the tip commit SHA of the
deleted branch (GitHub does not do this either).
N.B. there may be other conditions other than `HookEventDelete` where
the default branch ref needs swapped in, but this was sufficient for my
use case.
There is no fork concept in agit flow, anyone with read permission can
push `refs/for/<target-branch>/<topic-branch>` to the repo. So we should
treat it as a fork pull request because it may be from an untrusted
user.
`HookEventType` of pull request review comments should be
`HookEventPullRequestReviewComment` but some event types are
`HookEventPullRequestComment` now.
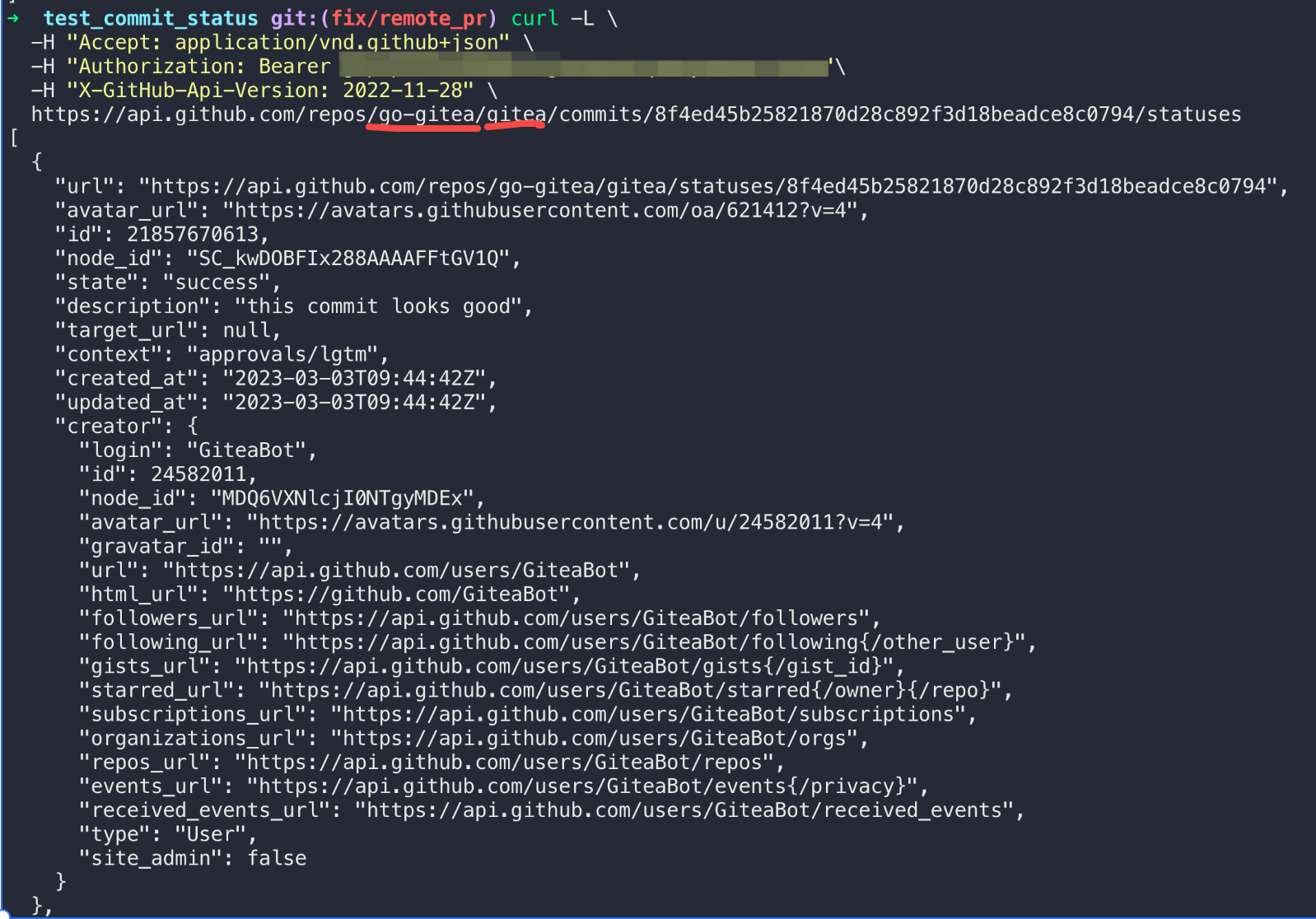
When creating commit status for Actons jobs, a payload with nil
`HeadCommit` will cause panic.
Reported at:
https://gitea.com/gitea/act_runner/issues/28#issuecomment-732166
Although the `HeadCommit` probably can not be nil after #23215,
`CreateCommitStatus` should protect itself, to avoid being broken in the
future.
In addition, it's enough to print error log instead of returning err
when `CreateCommitStatus` failed.
---------
Co-authored-by: delvh <dev.lh@web.de>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
In Go code, HTMLURL should be only used for external systems, like
API/webhook/mail/notification, etc.
If a URL is used by `Redirect` or rendered in a template, it should be a
relative URL (aka `Link()` in Gitea)
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
#21937 implemented only basic events based on name because of `act`'s
limitation. So I sent a PR to parse all possible events details in
https://gitea.com/gitea/act/pulls/11 and it merged. The ref
documentation is
https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows
This PR depends on that and make more detail responses for `push` events
and `pull_request` events. And it lefts more events there for future
PRs.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}